Fine tuning a model on the local machine
Mike Saunders · 5th June 2026
As part of the index cards project, we feed images of index cards to a vision language model in order to extract structured metadata - headings, corrections, manuscript numbers, folios, descriptions, etc.
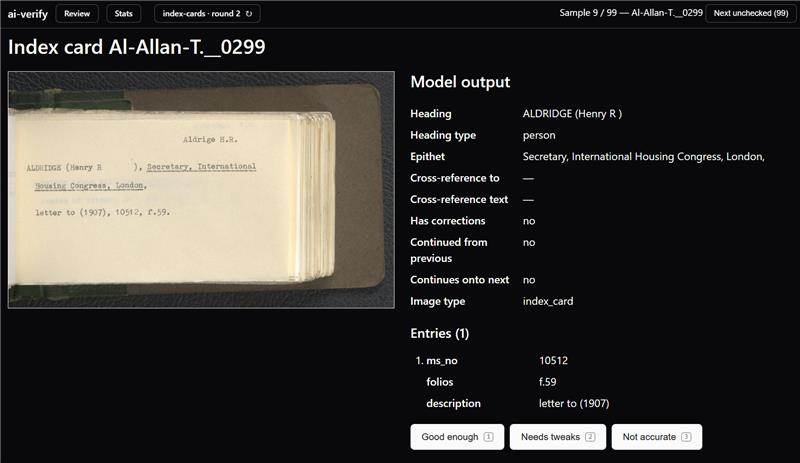
The trouble with these cards is the versos - all the blank pages and covers are scanned and sent to the model, and as it can sometimes see faint text, we get a lot of false positives.


Daniel did some training on a model to try and reduce these false-positives, but I found that a lot were still getting through. so I did the training again. i'll skip over the technical details for now and go to the headlines:
- Previously, 20% were false positives in the sample run. Now 0% are false positives.
- Every part of this pipeline has permissive licensing, allowing for open sourcing and sharing on Hugging Face.
- The fine tuning was done fully in house on the Framework AI machine (some parts of the previous training used Hugging Face jobs).
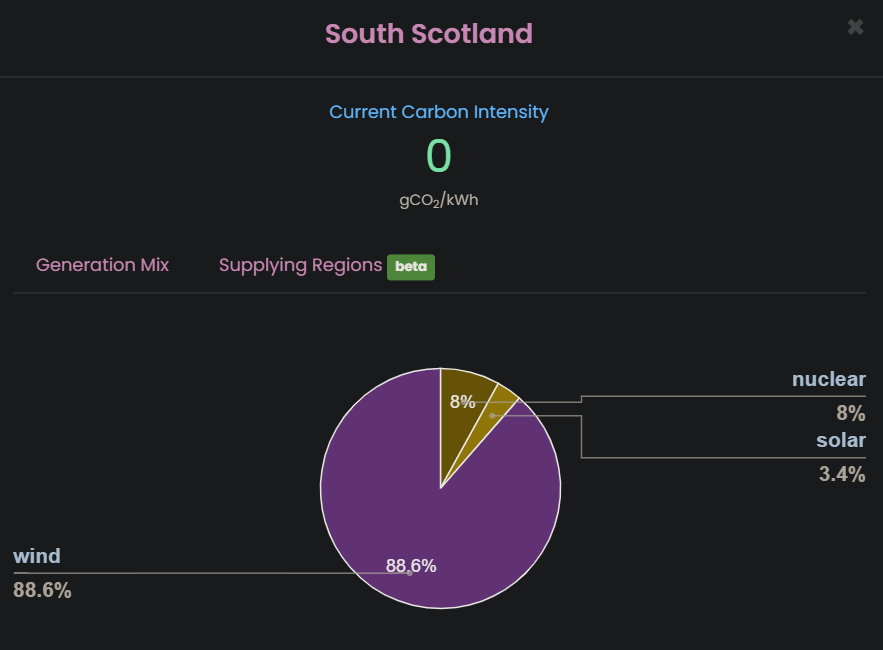
- Energy consumption was about 0.5 kWh. Because it was pretty windy yesterday, we can see from the Carbon Intensity API that South Scotland's grid was about 88% wind energy. Therefore the carbon cost of fine-tuning the model was close to zero.
Up until this point we have used the framework machine for inference - running pre-trained existing models to generate metadata outputs - but this is the first time it's been used to fine-tune a tool specific to our scans and requirements.
This isn't a flashy model, and literally just draws boxes around index cards, but I think it's kind of an exciting milestone.
