Reaching good enough
Mike Saunders · 25th June 2026
We had a bit of a breakthrough this week that I didn't think would happen with this round of testing - we reached 87.9% accuracy for model inference on the validation set for born digital monographs.
A recap of the pipeline
I've written about the process before, but a quick summary: - We recieve thousands of born digital monographs through Scottish Publishers through legal deposit, and many of these are through Scottish Government, Parliament, and local authorities. These range hugely in the amount of metadata provided or embedded in the document, and span everything from government reports to political party fliers, Edinburgh Festival brochures, and notices about upcoming vaccination days at local clinics. - We wanted to try and produce some basic automatic metadata extraction from these documents, with the understanding that it would not be perfect, but that it would contain enough information to make the documents easier to find and use through our catalogue. Access was the driving force of this metadata creation rather than 100% accuracy. - We took the first 3 pages and the last page of each document; fed these to a mixed model (vision and language); and wrote a simlple data schema and (less simple) prompt to extract the metadata. - We started with 50 documents, checked the results (using a custom quick-verify UI for cataloguers), tweaked the prompt and data schema, and repeated (using the paratext/colophon pipeline), adding an additional 50 documents each round, with the vague goal of reaching 80% accuracy.
Hitting the 80% threshold
We ran three rounds - the first hit 62% (50 documents), the second 71.5% (100 documents), and the third hit 87.9% accuracy (150 documents).
There's two reasons we hit the 80% threshold: technical and personal; or technical and organisational; or technical and social.
Technical
The jump between round 1 and round 2 was simply a heavy prompt tweak. If the metadata team found the model's output wasn't good enough, they could tick 'needs tweaks' or 'not accurate', and add notes as to why. We then used these notes to recognise patterns that could be used to improve the prompt.
The jump between round 2 and 3 was a prompt tweak, but I also noticed the sheer amount of 'ephemera' getting through - which we wouldn't usually catalogue individually - was dragging down the overall accuracy. So I made an adjustment to the schema that was only for pre-processing (it wouldn't be part of the output metadata), and added an instruction to the model to pre-classify the documents before outputting the metadata. This wasn't just a 'ephemera' or 'not ephemera', but a more structured way of pre-classifying the documents - mainly so it would be easier to spot errors in reasoning.
Personal/Organisational/Social
The first thing is having a team of cataloguers in the metadata team who were interested in doing the work. This makes the single most tangible difference between doing any of this, even if you've got the biggest computer and the most accurate model.
The second most important thing is including them as much as possible. There are a few days to do this, here's the two that I've found have been appreciated:
- Make a nice, simple UI for them to check the model's output, rather than asking them to, for example, dig through or write notes in an excel spreadsheet. It shows a bit of respect for their time, effort, and expertise.
- Demystify the prompt.
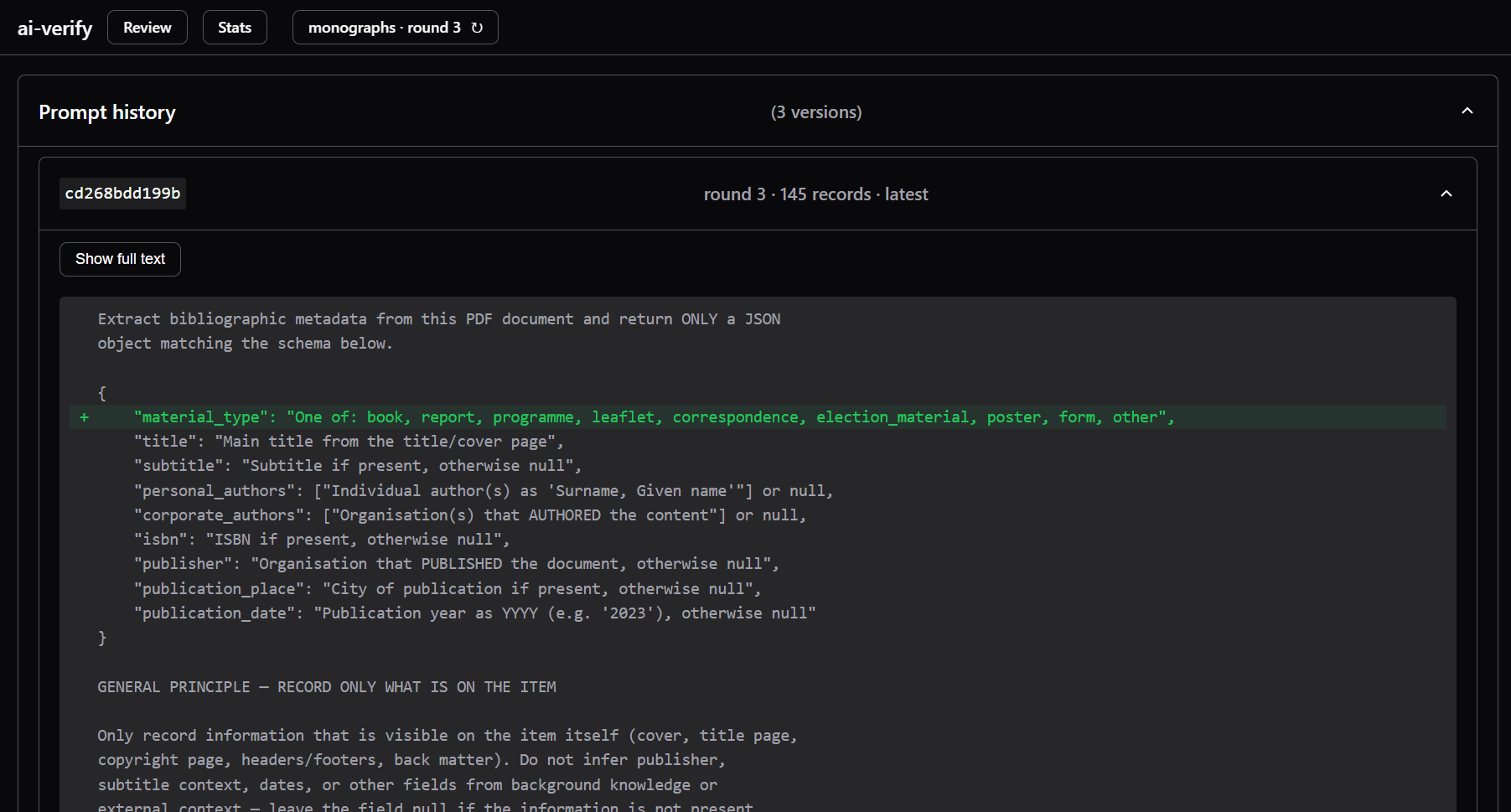
- Make an easy way for them to see the actual prompt, and the changes made to the prompt each time. Prompt engineering is not rocket science, and by showing them the prompt and the diffs/changes between each round, they can see how the model is working and why it's making the decisions it is - you can actively use their decisions and expertise to change what would may have previously been regarded as the code, and give them immediate feedback on their influence.
Having a team who interact in good faith with the model and the work will make a fundamental difference to the success of the feedback and the project in general. It begins the capacity to build trust, and also allows for failures. That's so important within an organisation that has never really done this before, within a sector that has never really done any of this before.
The next step is looking at everything we've got, running the model over the rest of the dataset and seeing how it performs with some spot checks; then converting the json to marc and putting some of this in our catalogue sandbox. Then we'll see how staff feel about it. We want to make sure that everyone involved is comfortable at each stage before moving on - it's the first of this type of workflow in the library, so we want to both treat it with care and learn from every stage.